|
|

|

|
| e-Pub |
Section: New Results
RGB-D based Action Recognition using CNNs
Participants : Srijan Das, Michal Koperski, François Brémond.
In the first half of the year, we focused on using the newly introduced Pose Machines [51] to extract skeletons from RGB frames. Then, our objective was to study how different skeleton extraction methods affect the performance of action recognition. For skeleton extraction from RGB data we used Pose Machines [51] and from Depth data we used Kinect sensors. Since, our final objective is to recognize actions from videos, we use an action recognition network proposed in [55]. This action network takes part patches (right hand, left hand, upper body, full body and full image) around the joints to produce CNN features. The framework considers both the appearance flow and the optical flow so as to produce the concatenated CNN features. These features followed by a max-min aggregation are used as an input of a SVM to classify actions.
Finally, we propose a fusion of classifiers trained based on each skeleton extraction methods discussed above to improve the action recognition performance. The framework is depicted in fig. 22. We validate our approach on CAD60, CAD120 and MSRDailyActivity3D, achieving the state-of-the-art results. We chose daily living action datasets due to its application to healthcare and robotics. The proposed framework has been published in AVSS 2017 [28].
|
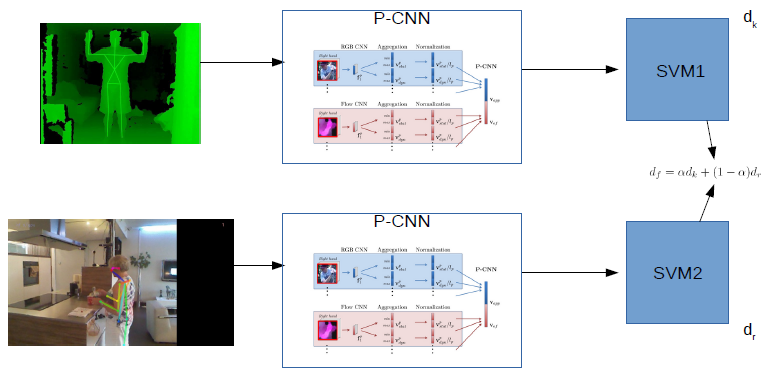
Though our proposed approach performs well on CAD60 and MSRDailyActivity3D, it does not perform well on CAD120 because of the wrong patches detected during the skeleton extraction technique. Moreover, we also observed that sometimes noisy skeletons results in better action recognition as compared to well detected skeletons. This is because, noisy skeletons include the objects incurred in the actions since we use part patches in the action recognition network. So, now we include the object reference as well by considering extra large part patches in our modified P-CNN network for action recognition.
Now, we are focusing on how to include temporal information for action recognition. In our recent work, we discuss the limitation of not taking the temporal information into account for action recognition. Our objective is to introduce the temporal evolution of skeleton sequences with Recurrent Neural Networks (RNNs).
This work has been done in collaboration with Francesca Gianpiero (Toyota Motors Europe).